Practices of an Agile Developer
Saturday, April 21, 2007
I just finished reading Practices of an Agile Developer (by Venkat Subramaniam & Andy Hunt) and I wanted to recommend it to those people who want to learn about the Agile process or just want to help improve their own code quality and performance. Of all the methodolgies and processes that make up Agile (or rather allow it to fit to your environment) there are a core set of practices that this book points out. It takes these practices and shows the reader how to apply them to their daily workload. Here's a great review of the book that I recommend as well (why should I write the review when someone has already done it for me?). Go out and buy this. It's worth the $30 price tag.
- Gilemonster
Labels: General
posted by Gilemonster @ 12:32 PM,
, links to this post
![]()
![]()
An ADO and VBScript Adventure
Saturday, October 28, 2006
In a recent work-related project I was asked to provide a simple VBScript code snippet that called a SQL stored procedure. No one knew what the stored proc looked like or even how it worked. To make matters worse, I am neither a T-SQL nor VBScript guru by any degree. The task of writing that small bit of code is the topic of this article. If you are a VBScript or ADO guru, you can stop here as you'll probably not learn anything. You might get a laugh out of it though. ;-) If you are new to writing ADO code in VBScript (as I was), read on as I'll show you some pitfalls and things I didn't know (but unfortunately hit).
The stored procedure in question lived on a SQL Server 2000 machine, and to my surprise, contained over 100 parameters (all of which contained "default" values but 1)! The only required parameter was a GUID and was easily found in another table. So I figured I would test the stored proc out first in Microsoft's SQL Query Analyzer and make sure it worked as described. With my very little SQL experience, I just created the syntax that would call the stored proc and pass in 1 GUID and 99 NULL values. I thought that a NULL value parameter would cause the stored proc to use its default value. Oh how I was wrong! Instead of using default values, NULL was treated as an acceptable value and therefore passed in to the remaining 99 parameters. You can imagine the damage that was done. I basically had used this stored proc to set every one of this table's foreign keys to NULL. So I pretty much destroyed the database. Nice... After many database restores, a coworker explained to me the problem with using NULL. The correct thing to do was to pass the T-SQL keyword DEFAULT as the parameter value and the stored proc will then use its default values (if any). Man, I felt like an idiot. What programmer thinks that NULL wouldn't be an acceptable value? ;-) Even though I was thoroughly embarrassed, I figured the frustration was over and that I was golden. So I proceeded to write the sample VBScript which would do the same thing as the code in Query Analyzer. Here's a subset of the code I wrote (error checking removed for simplicity):
Const adCmdStoredProc = 4
Const adGUID = 72
Const adParamInput = 1
Const adVarChar = 200
Const MyGuid = "1A8A3DA2-1564-40FA-8F4B-4B27B5B2BAD5"
'# Create your connection object to the SQL database
Dim objConnect
Set objConnect = CreateObject("ADODB.Connection")
objConnect.ConnectionString = "Provider=SQLOLEDB; " &_
"Data Source=MyServer; " &_
"Initial Catalog=MyDb; " &_
"Trusted_Connection=yes"
'# Setup your command object that will call the stored proc
Dim objCommand
Set objCommand = CreateObject("ADODB.Command")
objCommand.ActiveConnection = objConnect
objCommand.CommandType = adCmdStoredProc
objCommand.CommandText = "MyStoredProcName"
'# Supply the required parameters to the stored proc
Dim objParam1
Set objParam1 = objCommand.CreateParameter("@Param1", _
adGUID, _
adParamInput, _
, _
MyGuid)
objCommand.Parameters.Append objParam1
Dim objParam2
Set objParam2 = objCommand.CreateParameter("@Param2", _
adVarChar, _
adParamInput, _
32, _
"BlahBlah")
objCommand.Parameters.Append objParam2
objCommand.Execute
'# Tada! It should work right?
As you can see, I created ADODB.Connection and ADODB.Command objects. I then passed in only those values that I needed (just 2 in this case) for the stored proc to execute. The first of which was the only parameter that was required by the stored procedure. When I ran the code, all I did was foul up the database again. The parameters I supplied were passed in as the first and second parameters to the stored proc. It didn't even matter that I supplied the name of parameter as well. Wait, how can that be?!! Well of course, I was fuming after this. The deadline had passed and people were beginning to wonder why this little snippet of code wasn't complete yet. Drama sucks! After a few cigarettes and some time to calm down, I sat down with my favorite search tool. Google. So, as usual, I started googling, googling and more googling. On about the 5th try, I found a hit about 20 links down (who looks down 20 hits on a Google search?) that showed how to specify your Command.Parameters collection when you want to use the default value for some of the parameters. Here's the fix:
...
Dim objCommand
Set objCommand = CreateObject("ADODB.Command")
objCommand.ActiveConnection = objConnect
objCommand.CommandType = adCmdStoredProc
objCommand.CommandText = "MyStoredProcName"
objCommand.Refresh
...
objCommand.Parameters("@Param1") = MyGuid
objCommand.Parameters("@Param2") = "BlahBlah"
objCommand.Execute
The Refresh routine queries the database for the parameter list before you make your query. This means that you don't have to "create" any parameter objects for the Parameter collection that is in the Command object. All you have to do is assign a value to the parameters that don't define a default value. Everything else not assigned a value to will not be set and therefore the stored proc will use the default values it defined. So as usual, I learned something new. Oh well, I'm not a big fan of VBScript or stored procedures anyway. In fact, I think languages that aren't compiled were created by the Devil. ;-) Just kidding, they have their place and uses I guess. Anyways, here's what I can pass on to you (unless you just read this for a good laugh):
NULLis a valid value type when passed into a stored procedure parameter and therefore does override the default value (if one is defined). In a tool like Query Analyzer, you need to specify either theDEFAULTkeyword, or the@ParamName=DEFAULTalternative syntax. I'm sure there might be other ways to do this, but those are the ones I found.- In VBScript, make sure you query the database for a list of parameters before you try and pass them to a stored procedure (unless there are no parameters of course). You do this with the
ADODB.Command.Parameters.Refreshroutine, and then you will be able to supply only those parameters you need and the rest will be treated as having no value at all. A side benefit is not having to write the code that creates and defines those parameter objects.
This might have been a silly article, but maybe by some freak chance I'm not the only person in the world who didn't know that stuff. Hopefully somebody else will find it useful. Many more articles like this and people won't read this blog anymore. ;-) Until next time...
- Gilemonster
Labels: General
posted by Gilemonster @ 8:26 PM,
, links to this post
![]()
![]()
Know Your Data Structures: Queues and Stacks
Tuesday, August 08, 2006
Stacks
A stack is a dynamic linear data structure where insertion and deletion of items is already predetermined. This basically means that we already know where items are added and deleted before we perform the operation itself. Here's how it works. Stacks only allow you to insert and delete items from the top (or tail of the stack). This logic flow is called LIFO ("Last In First Out") and means that the deletion of an item from the stack is always the item that was most recently added. A good analogy that I've read is a stack of dishes in a restaurant's buffet line. New plates are added at the top of stack and when a customer grabs one, the top-most plate is removed. Insert and delete operations are called push and pop respectively and both are performed in constant time O(1).
When implementing a stack data structure, there are two main boundary conditions you need to account for: underflow and overflow. An underflow occurs when an empty stack is "popped." This means that a delete operation was attempted on an empty stack. An overflow occurs when a full stack is "pushed." This means that an insert operation was attempted on a full stack. Below, I have provided some pseudocode showing how a simple stack structure works:
void Push(int newValue)
{
if (Stack isn't full (e.g. overflow))
{
- Add item to top of stack
- Increment your top index value
}
}
void Pop(int & newValue)
{
if (Stack isn't empty (e.g. underflow))
{
- Remove item from top of stack and assign
to the newValue parameter
- Decrement your top index value
}
}
Queues
A queue is also a dynamic linear data structure with predetermined insertion and deletion operations. The main difference between a stack and queue is that a queue practices FIFO ("First In First Out"). This means that new items are added at the top of the queue (or tail) and are removed from the bottom (or head). A good analogy is your standard waiting line to get into the movie theater. You get in line at the end and wait until those customers before you have purchased tickets and walked away. Then you get to go next while the people who entered the line after you await their turn. Insert and delete operations are called enqueue and dequeue respectively and both are performed in constant time O(1) just like stacks.
Queues require slightly more work because we are required to keep up with both the beginning (the "head") and the ending (the "tail") of the structure in our implementations. With stacks, all we have to do is just make sure that the top-most element is within boundary limits. With queues, we are required to make sure that when an element is added, it goes in the tail's current location and when an item is removed, we have to make sure that the element in the head's current location is deleted. Also, the same boundary conditions in stacks exist for queues (e.g. underflows and overflows). Below, I have provided some pseudocode showing how a simple queue structure works:
void Enqueue(int newVal)
{
if (Queue isn't full (e.g. overflow))
{
- Add your value to the tail of the queue
- Increment your tail index (or wrap it)
}
}
void Dequeue(int & newVal)
{
if (Queue isn't empty (e.g. underflow))
{
- Remove item from queue and assign to the
newVal parameter
- Increment your head index (or wrap it)
}
}
Stacks and queues are simple and easy to use for certain programming projects (e.g. postfix/infix evaluations). The easiest implementation technique used for both is to use an array as the internal structure (my pseudocode examples use an array). There are more complex implementations but arrays are used more frequently because of the simplicity. As always, post comments if something isn't clear and I'll try to help out. If you'd like the full queue and stack class files (.h & .cpp) let me know and I'll provide a link to them. Until next time...
-Gilemonster
Labels: General
posted by Gilemonster @ 8:38 AM,
, links to this post
![]()
![]()
Know Your Data Structures: Hash Tables
Sunday, July 23, 2006
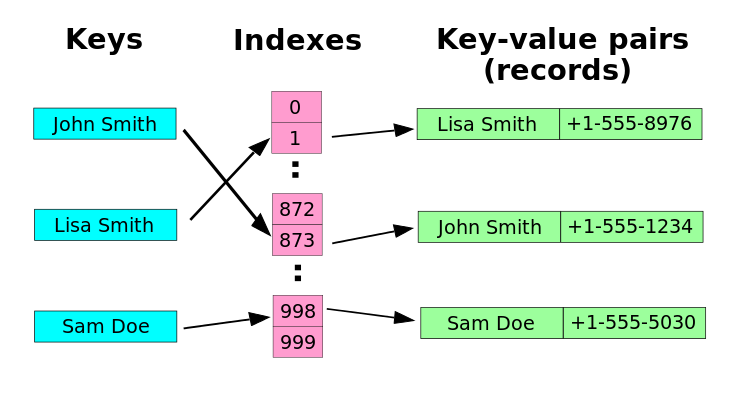
A Hash table is a data structure that associates keys to values (e.g. dictionary-like objects). It takes a key and maps that to an internally stored value. The mapping of the key to its location in the hash table is done via a hashing function. The hashing function attempts to transform a key into a unique location in the hash table. If this can be performed, insertions, deletions, and searches can be performed in O(1) time. This is because you are basically using direct addressing into the hash table's "array of values." This is similar to indexing a value in an array. When an array element is accessed, it is done in O(1) because you know the exact offset into the data structure (e.g. myarray[5]). You don't have to waste processing time searching for the key's matching value by traversing through the data structure (e.g. as in a linked list). Click here for a simple diagram which displays the internal structure of a hash table.
The problem with hash tables is when the hashing function cannot transform a key to a unique location in the hash table (e.g. two keys hash to the same hash table index). This is called a collision and there are a number of techniques are used to solve this problem. The two main techniques I will discuss here are called chaining and open addressing.
ChainingChaining basically uses a linked list as the structure to hold all the records that collide at the same index. When performing operations with a hash table that implements chaining, extra code is required to perform a second step in order to access, modify, or delete a key/value pair. This second step is the traversal of this "collided linked list" in order to find the appropriate location where an object can be accessed, modified, or deleted.
Of course there are advantages and disadvantages of using chaining as a collision resolution technique. Because we are operating on a linked list, we get the benefit of deletions being simple and quick (pointer reassignment). Unfortunately, we also inherit the disadvantages of standard linked list overhead and that traversal takes longer than with direct addressing.
Open AddressingOpen addressing involves actually storing the hashed index records within the internal hash table array. Collision is resolved through probing, which is the searching of alternate locations in the array. If an empty array slot is found, this signifies that there is no such key in the table. The main problem with open addressing is when the slots in the value array begin to fill up (called the load factor). As this increases, probing because expensive and can incur a large time cost. As a general rule, 80% load factor is about the time when open addressing becomes too expensive to use.
Know When to Use Hash Tables...- Hash tables are not the best solution for ordered data sets. Remember that hash tables store their values in pseudo-random locations and therefore accessing ordered data sets can be time intensive.
- Since hash tables can be time intensive in worst-case scenarios it is best to just use a simple array indexing structure if possible. They are usually faster.
- On average, hash table operations can be performed in O(1) time.
- Worst-case, hash table operations can be performed in O(n) time.
In general, I hope you can see that hash tables are an interesting data structure when used appropriately. They have the capability of providing O(1) time operations which is extremely nice in "dictionary-like" objects that contain a large number of records that need to be stored. But take care when using them by verifying that the hashing function is well written. This function is the single most important component to providing good hash table performance. Until next time...
-Gilemonster
Labels: General
posted by Gilemonster @ 7:18 PM,
, links to this post
![]()
![]()
.bat file continuation character
Friday, May 26, 2006
I've finally found the continuation character for continuing a line in a bat file. It is the caret "^".
Labels: General
posted by tac @ 6:24 PM,
, links to this post
![]()
![]()
Should architects code?
Tuesday, May 16, 2006
This is always an interesting discussion to me (since I am an architect). I just saw this article on this topic in Dr. Dobb's.
Personally, I think architects should be keep their fingers in the code to some extent. I just think it's difficult to architect/design a system if you don't know how it will be built. I don't write as much code as I used to, but I still like to stay involved and even participate in some coding and detailed design exercises from time to time.
Labels: General
posted by TigerEagle @ 3:31 PM,
, links to this post
![]()
![]()

{kind=link}