Know Your C++: Using Exceptions
Tuesday, July 25, 2006
As most of you already know, exceptions are errors or anomalies that occur during program execution. They are used as part of a programming philosophy that states, "You will not ignore this error scenario!" Rather than getting into why one would use exceptions, I am going to discuss a bit about their details and proper usage. The guts of C++ are always more interesting (right?).
How They WorkLets begin with our standard throw invocation. In C++, the first thing performed is a copy of the exception object thrown is created. This copy is then "returned" from the function initiating the throw expression (the "throwing" function's scope is exited immediately and he is popped off the call stack). This process is called stack unwinding and will continue until an appropriate handler is found that can catch the object type thrown. As part of stack unwinding, each object that is popped off the stack goes out of scope, and therefore its destructor is called (this is good). This ensures that objects are cleaned up as they go out of scope (assuming the popped object's destructor does not throw an exception as well - more about this in a bit).
If an appropriate exception handler is not found, the terminate() function is automatically invoked. By default, this calls the Standard C library function abort() which kills your application. As a side note, if an object's destructor throws an exception (nobody does that right?) terminate() is called as well. Therefore, the general process goes as follows:
- Function foo() throws an exception.
- That function and all objects local to it are destructed and popped of the call stack along with the foo() function itself.
- Then an appropriate handler is searched for all the way up the call stack until one (or none) is found.
- If this happens, terminate() is called which calls abort() and it sends your application packing.
Now that we see the general idea of how they work, we need to make sure we account for various pitfalls in their use. Because the proper use of exceptions is critical to an application's viability, it is imperative that we know these extra details. Therefore, I have provided a few tips on how to use exceptions below.
Catch Exceptions by ReferenceIn order to guarantee that all parts of your object are handled by a catch block, make sure that you catch your exceptions by reference. There are good reasons to do this. One, is that you avoid the normal overhead of an extra copy when the object is passed-by-value. Second, you ensure that any modifications provided to the exception object itself are preserved if the object needs to be re-thrown. Finally, you avoid the slicing of derived exception objects when base-class handlers catch them. Here is a quick sample of catching an exception by reference:
try
{
...
}
catch (MyException & e)
{
...
}
Never Let Exceptions Leave an Object's Destructor
We all hate memory leaks right? Well in order to prevent memory leaks with exceptions, you have to first make sure that your destructors do not throw them. For example, I have a class below, the MyLeakyClass class that is defined like this:
class MyLeakyClass
{
public:
MyLeakyClass();
~MyLeakyClass();
...
private:
wchar_t * szSimpleString1;
wchar_t * szSimpleString2;
};
MyLeakyClass::MyLeakyClass()
{
szSimpleString1 = new wchar_t[32];
szSimpleString2 = new wchar_t[32];
}
MyLeakyClass::~MyLeakyClass()
{
delete [] szSimpleString1;
delete [] szSimpleString2;
}
What happens if the first delete call above generates an exception? We know that execution stops immediately at the exception generating code and a matching exception handler is searched for by the caller (e.g. you called delete on an instance of MyLeakyClass). The first thing to notice is that the szSimpleString2 character array object is lost. He never is deleted and therefore you have a leak of the 32 bytes. Nice job, but it gets worse. What if the calling code was not your invocation of the delete operator? If it was say, a part of the stack unwinding by another exception being generated, your destructor's exception (the second exception in this example) will result in a call to the terminate() function as we mentioned earlier. Moreover, we know this means your application will most likely die. Therefore, best-case scenario here, we leak if we have dynamically allocated objects on the heap. Worst case is we leak and we die. Not a good combination. There is really only one solution to this problem if you do not want your application to die. You need a try/catch all which does nothing. This is the only way to guarantee that exceptions are not thrown from the handler and therefore no exceptions leave the destructor. It is not pretty and some of you will disagree with it, but here is a simple example of MyLeakyClass destructor rewritten:
MyLeakyClass::~MyLeakyClass()
{
try
{
delete [] szSimpleString1;
}
catch(...) {}
try
{
delete [] szSimpleString2;
}
catch(...) {}
}
Catch exceptions in order of object inheritance
When catching exceptions you have to understand that a handler will match the object type it is catches with the type of object being thrown. Like all objects in C++, a catch block which specifies a base class will match with a derived class object because of the is-a relationship. Therefore, you must order your catch blocks by the object hierarchy of the exception objects themselves. For example, if you have three exception object types:
class Base {};
class Derived : public Base {};
class DerivedAgain : public Derived {};
you need to provide your catch blocks in the following order:
try
{
...
}
catch (DerivedAgain & e)
{
...
}
catch (Derived & e)
{
...
}
catch (Base & e)
{
...
}
Starting with the most derived object and progressing up to the base-class, you are guaranteed to catch each and every type of the above three objects where appropriate. If you change that order, bad things can (and will) happen. For example, if you swapped the order of the Base and Derived handlers, your Derived objects would never be caught (by the Derived handler) because they would always be caught by the Base handler. This is because a Derived object is-a Base object.
Avoid exception specificationsException specifications are a mechanism that allows the programmer to declare the types (if any) of exceptions, a function will throw. In my opinion, they biggest benefit of using specifications is that it documents for a client/user what you throw. This is rather nice, but the adverse affect of using specifications greatly outweighs that benefit. The problem is when your function throws an exception that is not one of the specified types. Here is an example.
// function declaration...
unsigned long FooBar() throw(int);
// function definition...
unsigned long FooBar()
{
EvilExceptionThrower() // Might throw anything
}
What happens if EvilExceptionThrower() throws an exception of type std::runtime_error? FooBar() is defined to only throw exceptions of type int and therefore we enter the unknown. Because our function isn't supposed to throw std::runtime_error exceptions, the default behavior is to call terminate(). Oh yea, we know what happens next. You just killed your application, congratulations. Now, if you still like the specifications and want to use them, you have one solution. Provide a catch all handler in your function that makes sure only specified exceptions are thrown (you could also pray that nothing called in your function throws non-specified exceptions). Depending on your design, this could be good or bad. In general, catch all handlers are not elegant in the general sense. If you want your app to die, do not add the catch all. If your application should try to continue on, add 'em. In my opinion, it is preferable to add a comment in your function declaration, saying what type(s) of exceptions you throw. This way you do not limit your function and inadvertently kill your application.
In general, exceptions are a effective and useful programming philosophy that I have used a number of times. Like most things in C++, if used correctly and in the right circumstances, they perform their job well. Until next time...
- Gilemonster
Labels: C++
posted by Gilemonster @ 10:00 PM,
, links to this post
![]()
![]()
Know Your C++: The new operator and operator new
Monday, July 24, 2006
Make sure you know how the new operator works when you use it in your C++ programs. Here is an example of how it is normally used:
wchar_t * myString = new wchar_t[256];
Most C++ programmers are familiar with this call and will tell you that the new operator invokes the target object,s constructor. That constructor performs operations like initializing member variables and whatnot. Yes, this is true, but how is this memory allocated and who allocates it?
This task is performed by a call to operator new (could the names be more confusing?). You can think of this as like a call to malloc(). operator new is usually declared like this:
void * operator new(size_t size);
The return type is void* because it returns a pointer to raw, uninitialized memory (on the heap or free store). You will also notice that the size_t parameter actually tells the routine how much memory to allocate. In the case where operator new cannot allocate the desired size, it will either return NULL or throw an exception. Now that we know who actually allocates the memory for the new operator, let us look at how that memory is allocated.
When a heap allocation request is invoked, a scan is performed that looks for a sufficiently large chunk of contiguous memory. This entails traversing the heap through pointers that point to the next areas on the heap that contain free memory blocks. When a sufficiently sized block is found, the memory is "tagged" with a size value (the boundary of where this allocated chunk ends) and pointers are rearranged so that this memory block is not seen as "free" (until we delete it later). Finally, a pointer to the starting address of this newly allocated section on the heap is then returned to the caller of operator new (in our case that is the new operator).
Now that our starting memory address is returned we can continue with the last task that the new operator must perform. This final step is the initialization of the allocated memory via invocation of the target object's constructor.
When a program is finished with its dynamically allocated memory, it must be manually released by invoking the delete operator. As with the new operator, a similar process occurs when operator delete is called by the delete operator (yes, this naming is just as confusing as with new). When this occurs, the deallocated memory is added back to the top of the heap so it can be reused.
To summarize, we can see that a call to the new operator, always performs the following two operations:
- Call the operator new function which returns a pointer to the starting address of an uninitialized memory block on the heap, and
- Call the target object's constructor to initialize that memory block.
Knowing this type of information is a must for C++ programmers. Even though you may never need to overload operator new (you can,t override the new operator) it is useful information for understanding how C++ allocates and instantiates user-defined objects.
-Gilemonster
** Update **
There are a couple more items to mention that have come from comments and other readers.
- First of all when creating an array of objects, the new operator actually invokes operator new[]. As Chris added below, this is commonly known as array new which further confuses programmers.
- Second, the new operator doesn't always allocate memory via operator new if placement new is invoked instead. You can override operator new with an additional void* parameter that is a block of memory that has already been allocated. This allows the programmer to provide a block of memory for reuse and therefore not perform the standard allocation that the object requires.
Labels: C++
posted by Gilemonster @ 8:37 PM,
, links to this post
![]()
![]()
Know Your Data Structures: Hash Tables
Sunday, July 23, 2006
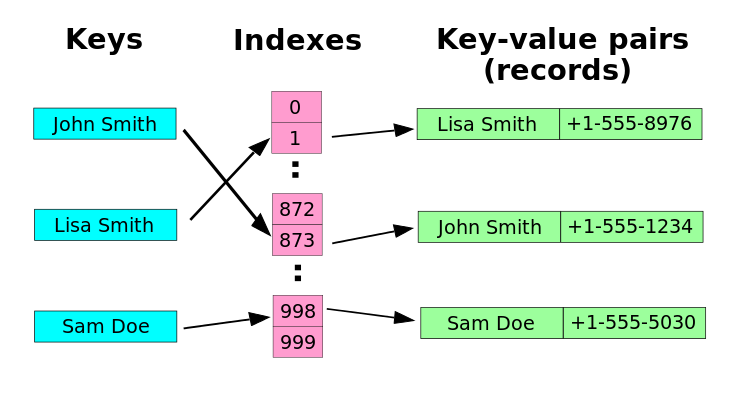
A Hash table is a data structure that associates keys to values (e.g. dictionary-like objects). It takes a key and maps that to an internally stored value. The mapping of the key to its location in the hash table is done via a hashing function. The hashing function attempts to transform a key into a unique location in the hash table. If this can be performed, insertions, deletions, and searches can be performed in O(1) time. This is because you are basically using direct addressing into the hash table's "array of values." This is similar to indexing a value in an array. When an array element is accessed, it is done in O(1) because you know the exact offset into the data structure (e.g. myarray[5]). You don't have to waste processing time searching for the key's matching value by traversing through the data structure (e.g. as in a linked list). Click here for a simple diagram which displays the internal structure of a hash table.
The problem with hash tables is when the hashing function cannot transform a key to a unique location in the hash table (e.g. two keys hash to the same hash table index). This is called a collision and there are a number of techniques are used to solve this problem. The two main techniques I will discuss here are called chaining and open addressing.
ChainingChaining basically uses a linked list as the structure to hold all the records that collide at the same index. When performing operations with a hash table that implements chaining, extra code is required to perform a second step in order to access, modify, or delete a key/value pair. This second step is the traversal of this "collided linked list" in order to find the appropriate location where an object can be accessed, modified, or deleted.
Of course there are advantages and disadvantages of using chaining as a collision resolution technique. Because we are operating on a linked list, we get the benefit of deletions being simple and quick (pointer reassignment). Unfortunately, we also inherit the disadvantages of standard linked list overhead and that traversal takes longer than with direct addressing.
Open AddressingOpen addressing involves actually storing the hashed index records within the internal hash table array. Collision is resolved through probing, which is the searching of alternate locations in the array. If an empty array slot is found, this signifies that there is no such key in the table. The main problem with open addressing is when the slots in the value array begin to fill up (called the load factor). As this increases, probing because expensive and can incur a large time cost. As a general rule, 80% load factor is about the time when open addressing becomes too expensive to use.
Know When to Use Hash Tables...- Hash tables are not the best solution for ordered data sets. Remember that hash tables store their values in pseudo-random locations and therefore accessing ordered data sets can be time intensive.
- Since hash tables can be time intensive in worst-case scenarios it is best to just use a simple array indexing structure if possible. They are usually faster.
- On average, hash table operations can be performed in O(1) time.
- Worst-case, hash table operations can be performed in O(n) time.
In general, I hope you can see that hash tables are an interesting data structure when used appropriately. They have the capability of providing O(1) time operations which is extremely nice in "dictionary-like" objects that contain a large number of records that need to be stored. But take care when using them by verifying that the hashing function is well written. This function is the single most important component to providing good hash table performance. Until next time...
-Gilemonster
Labels: General
posted by Gilemonster @ 7:18 PM,
, links to this post
![]()
![]()

{kind=link}