Know Your Data Structures: Hash Tables
Sunday, July 23, 2006
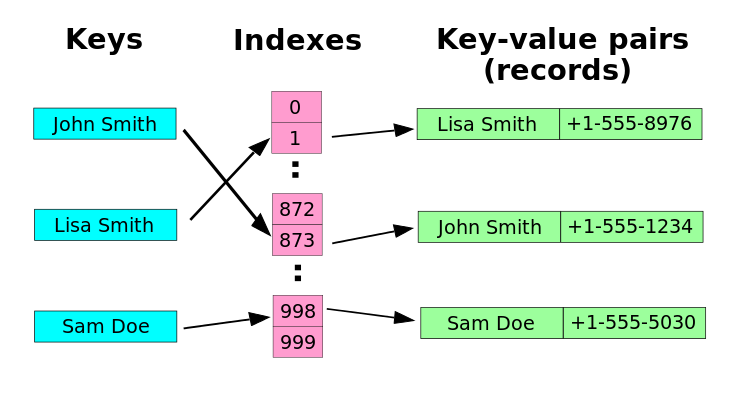
A Hash table is a data structure that associates keys to values (e.g. dictionary-like objects). It takes a key and maps that to an internally stored value. The mapping of the key to its location in the hash table is done via a hashing function. The hashing function attempts to transform a key into a unique location in the hash table. If this can be performed, insertions, deletions, and searches can be performed in O(1) time. This is because you are basically using direct addressing into the hash table's "array of values." This is similar to indexing a value in an array. When an array element is accessed, it is done in O(1) because you know the exact offset into the data structure (e.g. myarray[5]). You don't have to waste processing time searching for the key's matching value by traversing through the data structure (e.g. as in a linked list). Click here for a simple diagram which displays the internal structure of a hash table.
The problem with hash tables is when the hashing function cannot transform a key to a unique location in the hash table (e.g. two keys hash to the same hash table index). This is called a collision and there are a number of techniques are used to solve this problem. The two main techniques I will discuss here are called chaining and open addressing.
ChainingChaining basically uses a linked list as the structure to hold all the records that collide at the same index. When performing operations with a hash table that implements chaining, extra code is required to perform a second step in order to access, modify, or delete a key/value pair. This second step is the traversal of this "collided linked list" in order to find the appropriate location where an object can be accessed, modified, or deleted.
Of course there are advantages and disadvantages of using chaining as a collision resolution technique. Because we are operating on a linked list, we get the benefit of deletions being simple and quick (pointer reassignment). Unfortunately, we also inherit the disadvantages of standard linked list overhead and that traversal takes longer than with direct addressing.
Open AddressingOpen addressing involves actually storing the hashed index records within the internal hash table array. Collision is resolved through probing, which is the searching of alternate locations in the array. If an empty array slot is found, this signifies that there is no such key in the table. The main problem with open addressing is when the slots in the value array begin to fill up (called the load factor). As this increases, probing because expensive and can incur a large time cost. As a general rule, 80% load factor is about the time when open addressing becomes too expensive to use.
Know When to Use Hash Tables...- Hash tables are not the best solution for ordered data sets. Remember that hash tables store their values in pseudo-random locations and therefore accessing ordered data sets can be time intensive.
- Since hash tables can be time intensive in worst-case scenarios it is best to just use a simple array indexing structure if possible. They are usually faster.
- On average, hash table operations can be performed in O(1) time.
- Worst-case, hash table operations can be performed in O(n) time.
In general, I hope you can see that hash tables are an interesting data structure when used appropriately. They have the capability of providing O(1) time operations which is extremely nice in "dictionary-like" objects that contain a large number of records that need to be stored. But take care when using them by verifying that the hashing function is well written. This function is the single most important component to providing good hash table performance. Until next time...
-Gilemonster
Labels: General
posted by Gilemonster @ 7:18 PM,
![]()
![]()

{kind=link}